一、由scope(“prototype”)引发
- 昨天峰哥说了一个tag上必须加@scope(“prototype”)这样一个注解 。这个注解是将该类以多例的方式注入spring容器,能够解决多线程访问的线程安全问题;原本v52以前我们的action上也有这样的注释——因为Struts是类级别共享资源,所以在多线程访问时同样会有线程安全问题;修改为spring-mvc之后 ,spring-mvc是方法级别共享资源。所以不存在线程安全问题,因此不用加这样的注解。但是@scope(“prototype”)标注的类不应该被@autowired注入到其他类中,否则当有循环依赖的情况发生时,spring容器会无法初始化,抛出BeanCurrentlyInCreationException异常(参考开涛的博客-跟我学spring3 第三章3.2)
- 那么什么是循环依赖?
以maven项目为例,a项目依赖b,b项目依赖c,c项目依赖a,形成了一个闭合环就是循环依赖:
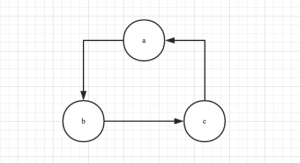
依据maven的生命周期,a项目在进行打包或者安装操作时,需要根据依赖先打包或者安装b,b项目在打包或安装时,需要先打包或安装c,c项目在打包或者安装时,需要先打包项目a;此时就会无限的循环下去直至内存溢出。
以上这种循环依赖无解。如果发生这种情况,一定是我们抽象的不对,假如a,b,c三个项目有共有的依赖,为什么不把他们抽象出来一个单独的项目d来由a,b,c共同依赖呢?
以上是使用maven项目构建时的一个小案例,上次峰哥再讲maven的时候我也提及过,我们在使用maven构建项目时可以考虑按功能抽象,也可以考虑按类型(core与模板分离)抽象。
循环依赖在任何具有依赖关系的技术以及体系中都存在。我们知道开发中如果表示类与类的关系时有以下几种表达方式:
泛化 、继承、实现、依赖、关联、聚合、组合
(参考文档http://www.cnblogs.com/olvo/archive/2012/05/03/2481014.html)
比如我们在将对象实例化并注入spring容器中时,会有一些相应的依赖关系。
因为scope是singleton的 所以这种循环依赖没有报错(会在实例化过程中提供标识,全容器可见:参考开涛博客第三章3.2)假设此时有任意一个被注入的类scope是prototype的,就不会提供这种全容器可见的标识,因此会抛出上述异常。
因此在设计类的时候,也可以抽取公共部分把循环依赖改变成单向的依赖,这样反而更符合逻辑,更符合开发的规范。
我们从上面的描述,可以理解到面向对象编程存在依赖关系时,应尽量避免循环依赖,从类结构、包结构、项目结构都要尽量避免有循环依赖的出现。
在v62的开发时,会引入一个测试代码质量的工具jdepend,这个大家可以作为一个研究院的课题研究jdepend的使用。
二、我的思考
- 接口实现类空实现
我们在写一个功能的时候,包括我也经常做一下操作:在orderController中调用orderManager的一个没有的方法,然后直接在接口中直接增加一个方法,导致StoreOrderManager需要增加一个空实现的方法。
先说说这样做的缺点:会给我们的代码增加很多的冗余,我们的代码本身就很臃肿,一个类1500行,可读性差,可维护性差。
在开发过程中,我们要优先遵循最基本的六大开发原则:开闭原则、接口隔离原则(依赖最小接口)、单一职责原则(一个类要有一组相同功能)、依赖倒置原则(依赖于抽象,不依赖具体)、里氏替换原则(具体实现应该可以互相替换而不被依赖者察觉)、迪米特原则(尽少知道)
还有其他各种原则:我整理了一下,认为这两个比较重要:apo(Avoid Premature Optimization避免提前优化)原则、dry(Don’t repeat yourself)原则
从哪些方面来遵守这样的原则呢?
我们首先要抽象一个service层。我发现,我们之前的代码由于各种历史原因,有的校验在controller中进行,并且有的controller中还包含了部分业务逻辑,这样做是不合理的。Controller是一个控制中心,只负责各种功能性代码的调用与执行;而manager中除了操作数据库,还要处理业务,首先就违背了单一职责、接口隔离、迪米特等原则,再深层次的考虑,会使我们的维护变得困难,对我们功能的扩展造成麻烦。
因此我的构想,在未来的6.3 或者7.0版本(过年前后),所有人这个时间都不要提交代码,大约7-10天的一个周期,从包结构上以模块划分、降低包之间的耦合,从类代码上抽象出一个service层,controller中只写调度,service层只写逻辑,dao层只操作数据库—-从各个角度看,这样更合理;以前我工作的公司都是这么做的,从可用性来讲也存在一定的可行性。在重构期间我们遵循上述八条开发原则,将接口拆分成最小单位,实现拆成最小单位,职责拆成最小单位,从结构上来对我们的代码进行整体优化。
- 在讲一点开发体会。
1) 关于脑回路:
举个例子,项目经理说,李冰长得好漂亮。
这个时候,郑皓的脑回路是这样的:
李冰—-漂亮—-泡她
我的脑回路
李冰—-漂亮—-范冰冰—-李晨—-有好车—-阿斯顿马丁—-帕加尼—-意大利—-AC米兰—-巴乔……
所以我们一个团队在共同开发的一款产品的时候,会遇到一个问题,项目经理分配的任务有可能没有按照预期的方向进行。所以此时要实时沟通。但是实时沟通的成本太高,所以我们要基于约定来进行开发。约定就包括了流程图,pdm,原型,优秀的开发者还会涉及uml图。
约定好这些之后,才可以进行开发,细节上可以讨论,但是大原则是基本不变的。这有助于提高我们的开发效率。同时文档齐全,交付时连文档一起交付。
开发完成后还要写一个简单的功能说明文档。
失败的案例。
我们所有的软件工程讲的这些工程学的东西,无非是为了更好更快更高质量的生产,那么放入到程序中质量的体现就是代码的复用性以及扩展性(这里还要加上易用性)。
我在设计“装修”功能时,设计的时候,充分的考虑到了可能的扩展,提前预留了一些扩展的字段;现在看来,这种做法是违反我们开发的原则的(避免提前优化)。
在设计的时候为了开发的方便性,暴露了很多内部逻辑给前端人员,这样用起来很困难。
封装可以解决易用的问题。
预告,下次part2将maven多模块项目的真实面目,敬请期待。







